


II. Développement de plug-in managé▲
- La classe Metadata (métadonnées) - Cette classe est responsable de l'exposition des caractéristiques de l'algorithme et créer des objets algorithmes.
- La classe Algorithm (algorithme) - Cette classe détecte, conserve et utilise les configurations contenues dans les données.
- La classe Navigator (navigateur) - Cette classe est responsable de l'affichage des configurations trouvées dans la classe Algorithm.
Pour plus de détails, on se reportera au Tutoriel de l'algorithme API plug-in managé de data mining dans http://www.sqlserverdatamining.com/
II-A. Bibliothèque IMSL C# : Intégration de ClusterKMeans▲
Un tutoriel pour la construction d'un algorithme plug-in managé fourni par Microsoft comprend un exemple d'intégration d'un algorithme simple dans SQL Server Analysis Services. Le reste de ce chapitre explique le processus d'intégration pour la classe ClusterKMeans de la bibliothèque IMSL C#.
Il est recommandé de suivre les étapes du tutoriel de l'algorithme plug-in managé de data mining pour créer le shell plug-in. Ce code souche servira comme modèle pour développer l'algorithme ClusterKMeans.
II-B. Démarrage▲
- Créez un nouveau répertoire appelé VNIClusterKMeans et copiez-y les fichiers et réglages du shell plug-in. Le shell plug-in est une solution créée en Microsoft Visual Studio 2005.
- Changez toutes les références du shell name vers VNIClusterKMeans : cela signifie renommer la solution, le projet, le fichier de signature et toutes les références dans les propriétés du projet.
- Assurez-vous que le projet est signé et que les étapes post-construction qui enregistrent l'assemblage dans le GAC sont énumérées dans les propriétés du projet.
- La solution doit avoir deux projets : DMPluginWrapper et VNIClusterKMeans. De plus, VNIClusterKMeans doit référencer le projet DMPluginWrapper. DMPluginWrapper est un assemblage COM interop qui traduit les appels COM de l'Analysis Services Server vers l'algorithme de plug-in managé. Il est disponible gratuitement dans le cadre du téléchargement de Algorithme API plug-in managé de data mining pour SQL Server 2005.
Note : Les classes Metadata, Algorithm et AlgorithmNavigator supportent de nombreuses fonctions, mais ce document ne décrira que les fonctions qui ont besoin d'être modifiées pour ClusterKMeans.
II-C. Changements des métadonnées (Metadata.cs)▲
Pour rendre le code managé visible au sous-système COM, décorez la classe Metadata avec [ComVisible (true)] et [Guid (<unique_id>)]. Dans ce cas, unique_id s'obtient en sélectionnant Tools Create GUID et en copiant l'unique_ID dans la classe Metadata. Votre déclaration devrait ressembler à ceci :
[ComVisible(true)]
[Guid("891DF04A-6B01-4125-B78E-C6DD8DB93471")]
[MiningAlgorithmClass(typeof(Algorithm))]
public class Metadata : AlgorithmMetadataBaseAjoutez un constructeur à la classe Metadata. Ce constructeur peut appeler une fonction qui déclare tout paramètre que l'utilisateur pourrait avoir le droit de fixer avant d'appeler l'algorithme. Cela survient habituellement à partir du studio de développement BI ou à partir d'une application client telle que Microsoft Excel. Le code suivant permet aux utilisateurs de fixer la variable cluster_count à partir des applications client.
Public Metadata()
{
Parameters = DeclareParameters();
}
Static public MiningParameterCollection DeclareParameters()
{
MiningParameterCollection parameters = new MiningParameterCollection();
MiningParameter param;
// Exemple de population complète d'un paramètre dans un constructeur
param = new MiningParameter(
"CLUSTER_COUNT",
"Number of Clusters",
"3",
"(0.0, ...)",
true,
true,
typeof(System.Int32));
parameters.Add(param);
return parameters;
}Modifiez la fonction GetServiceName pour retourner le nom du nouvel algorithme : VNI_ClusterKMeans. Changez aussi GetDisplayName et GetServiceDescription selon votre algorithme.
Modifiez GetParametersCollection pour retourner les paramètres.
Modifiez ParseParameterValue pour analyser les valeurs de paramètre entrées par les utilisateurs.
II-D. Changements d'algorithme (Algorithm.cs)▲
Cette classe met en ouvre des tâches spécifiques de l'algorithme. Elle est responsable de l'entraînement de l'algorithme, de la détection de tout modèle dans les données et de la prédiction de valeurs par utilisation de l'algorithme entraîné.
II-E. Entraînement et persistance de modèles▲
L'entraînement pour la classe ClusterKMeans comporte trois phases :
II-E-1. Première phase▲
Dans la première phase, vous collecterez les données présentes dans tous les cas d'entraînement. Un Cas est un type de donnée au sein du cadre d'application Analysis Services. Vous pouvez vous représenter un Cas dans une rangée dans une base de données relationnelle. Pour plus d'informations, reportez-vous à l'aide Microsoft Data Mining Help.
Pendant l'entraînement, il vous sera présenté un Cas à la fois. Il vous faudra parcourir tous les Cas et créer une sorte de stockage pour toutes les données présentes dans chaque Cas. Les données collectées seront formatées et utilisées comme argument d'entrée dans la routine ClusterKMeans. Il faut noter qu'il y a perte de performances avec l'approche qui consiste à collecter des données à partir des Cas. Habituellement, les algorithmes traitent directement avec les Cas et ne comportent pas d'étape intermédiaire d'initialisation des données pour les transférer à un algorithme. Toutefois, cette transformation nous permet de profiter des interfaces de programmation existantes de la Bibliothèque IMSL C# sans aucune modification.
- InsertCases - Cette fonction est le point d'entrée de l'entraînement de l'algorithme. Dans cette fonction, vous créerez un nouveau CaseProcessor pour traiter chaque Cas.
- ProcessCase - Cette fonction s'occupe de véritablement traiter un Cas. Dans cette fonction, vous devrez extraire les données du Cas et les conserver dans une sorte de réservoir que l'on pourra retrouver par la suite. Dans l'exemple ClusterKMeans, on a utilisé un objet VniStore pour stocker les valeurs des données. Pour plus de détails, on se reportera à "ClusterKmeans code" dans l'Annexe.
II-E-2. Deuxième phase▲
Dans la deuxième phase, vous formaterez les données collectées dans la première phase, vous exécuterez l'algorithme, définirez les modèles de données et associerez les données à chaque modèle.
Les données collectées ont besoin d'être formatées pour être utilisées comme argument d'entrée dans l'algorithme. Dans le cas de ClusterKmeans, les données ont besoin d'être transformées en un ensemble à deux dimensions. Reportez-vous à la documentation de ClusterKmeans pour plus d'explications sur les arguments disponibles. Une fois les données formatées, on peut exécuter l'algorithme. Après l'exécution, vous travaillerez avec les résultats issus de l'algorithme pour définir les modèles de données. Il vaut mieux définir un objet pour représenter un modèle. Pour ClusterKMeans, on a utilisé un objet Cluster (classe) pour représenter un modèle. Cette classe contient toutes les informations liées à ce modèle, telles que les données et les statistiques. Par exemple, si ClusterKMeans détecte trois modèles, vous aurez trois objets Cluster pour représenter chacun des modèles détectés. Une fois l'objet défini pour représenter un modèle, il vous faudra peuple l'objet avec les données associées à ce modèle/cluster spécifique.
- InsertCases - Modifiez le code source pour ajouter la deuxième phase qui exécute l'algorithme et définit les modèles.
Pour ClusterKMeans, un objet VNIStore stocke les données de la première phase, et dans la deuxième phase exécute la routine et associe les données à chaque modèle détecté. Pour plus de détails, on se reportera à "ClusterKmeans code" dans l'Annexe.
II-E-3. Troisième phase▲
Dans la troisième phase, vous fixerez les statistiques pour chaque modèle ou cluster. Cela inclut de fixer le nombre d'articles dans un modèle, min, max, variance et probabilité pour chaque attribut. On peut se représenter un attribut comme une colonne dans une rangée de données. L'idée est de fixer la distribution de cluster qui sera utilisée par la méthode de prédiction d'Analysis Services. Pour effectuer cette tâche, il vous faudra ajouter une fonction à votre objet modèle (cluster) pour mettre à jour toute statistique en rapport. Reportez-vous à la fonction updateStats dans la classe Cluster (voyez en Annexe pour les détails).
II-F. Persistance de modèles▲
L'objectif de la persistance est de sauvegarder toutes les informations nécessaires pour qu'elles puissent être chargées plus tard. L'API SQL Server Analysis Services fournit PersistenceWriter et PersistenceReader pour effectuer ces tâches. La classe Algorithm doit être utilisée pour sauvegarder toute information globale, mais les informations spécifiques au modèle doivent être déléguées à la classe du modèle. Pour ClusterKMeans, l'objet Cluster est responsable de l'écriture et du chargement des informations spécifiques au modèle.
Les fonctions que vous aurez besoin d'annuler sont SaveContent et LoadContent.
II-G. Prédiction▲
Dans le paradigme Analysis Services, prédire signifie retourner un histogramme (distribution) pour l'attribut cible. Pour ClusterKMeans, il vous faudra déterminer l'appartenance au cluster des nouvelles données puis déléguer la tâche de prédiction à ce cluster qui, en retour, retournera les statistiques issues de la troisième phase du processus d'entraînement du modèle.
- Predict - Cette fonction est responsable de la détermination de l'appartenance au cluster et de la délégation de la prédiction à ce cluster.
- Cluster.predict - Cette fonction est responsable du retour des statistiques déterminées dans la troisième phase du modèle d'entraînement.
II-H. Changements du navigateur d'algorithmes (AlgorithmNavigator.cs)▲
Cette classe est responsable de l'exposition des modèles détectés par l'algorithme plug-in. SQL Server Analysis Services utilise un objet Navigator (cette classe) pour exposer les modèles. Cet objet a l'aspect d'une structure arborescente. Par conséquent, il peut utiliser la notion de noud pour afficher des propriétés de noud, et il permet aussi d'alterner entre noud parent ou noud enfant du noud actuel.
L'implémentation de la classe Navigator dépend de la Visionneuse que vous utiliserez pour les modèles que vous aurez détectés. Par défaut, Microsoft fournit plusieurs Visionneuses pour afficher les clusters : modèles Naïve Bayes, etc. Pour ClusterKMeans, la visionneuse Microsoft par défaut a été utilisée pour afficher les modèles détectés. Le code pour implémenter l'objet Navigator pour la visionneuse est disponible comme exemple en ligne et son listing figure aussi dans "Un tutoriel pour construire un algorithme plug-in managé" (cf. référence). Puisque ce code est disponible, les détails ne figurent pas dans ce chapitre car il n'y a aucun changement apporté à ce code. Néanmoins, il se peut que vous ayez à modifier des parties de ce code si une visionneuse personnalisée est développée pour les modèles de données détectés.
- MetaData.GetViewerType - Fixe le type de visionneuse utilisé pour afficher les modèles de données.
- MetaData.GetServiceType - Décrit la classe d'algorithmes qui inclut votre algorithme. Pour ClusterKmeans, c'est ServiceTypeClustering.
- MetaData.GetSupportedStandardFunctions - Inclut le support des fonctions spécifiques du clustering.
- Algorithm.GetNavigator - Retourne l'objet navigateur. Pour ClusterKMeans, retourne la classe AlgorithmNavigator.
II-I. Enregistrer l'algorithme avec Analysis Services▲
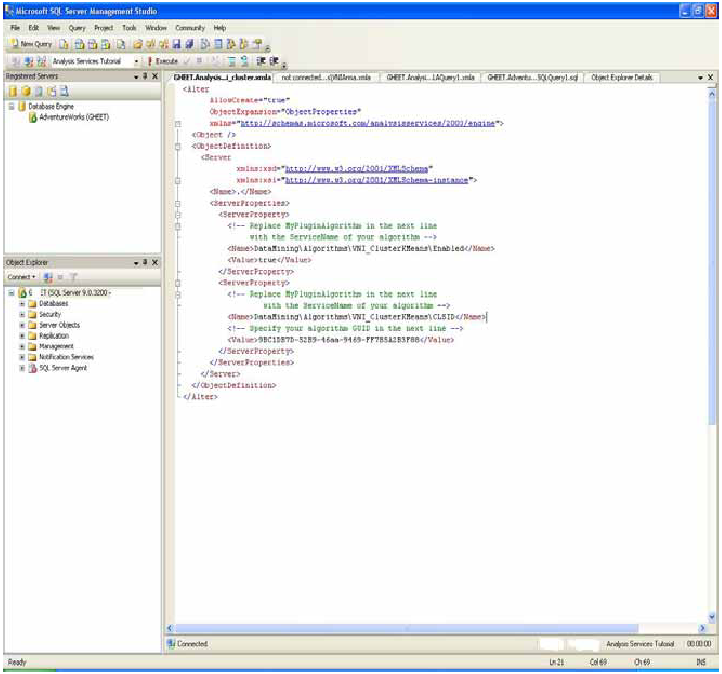
Cette étape permet à votre algorithme d'être utilisé par Analysis Services. Pour charger l'assemblage que vous avez construit dans Analysis services, il doit être visible dans le Global Assembly Cache (GAC). Les commandes post-construction dans les propriétés du projet devraient effectuer cette étape ; si vous avez des problèmes, assurez-vous que les étapes post-construction sont exactes et pointent sur un emplacement valide. Une fois que les assemblages sont visibles dans le GAC, il vous faudra utiliser le modèle XMLA fourni dans le document en ligne "Un tutoriel pour la construction d'un algorithme plug-in managé" (reportez-vous au chapitre Référence dans cette publication). Veillez à modifier le modèle en conséquence pour contenir une description de votre algorithme.
- Lancez le studio de management SQL Server.
- Connectez-vous au serveur cible Analysis Services.
- Sélectionnez File New Analysis Services XMLA Query.
- Collez la déclaration XMLA.
- Exécutez la déclaration.
Ensuite, il vous faudra redémarrer Analysis Service. Sélectionnez Control Panel Administrative Tools Services SQL Server Analysis Services (MSSQLSERVER) et relancez le service. à ce moment, votre algorithme nouvellement créé devrait être accessible à tous les clients qui se connectent à Analysis Services.
II-J. Debogage▲
Pour déboguer votre algorithme, vous devez d'abord l'enregistrer avec Analysis Services (cf. supra). Après enregistrement, sélectionnez Debug Attach pour le traiter à partir de l'environnement Visual Studio. Il apparaît la boîte de dialogue Attach To Process. Dans le champ de texte Attach To, assurez-vous que le code managé a été sélectionné. Parmi les processus disponibles, sélectionnez le processus msmdsrv.exe. Après cette sélection, vous devriez vous retrouver dans la session Debug où vous devriez pouvoir effectuer vos tâches normales de débogage. Pendant une session debug, une application client doit utiliser votre algorithme pour exécution pour s'arrêter à tout point d'interruption valide. Notez que toute modification de votre algorithme nécessitera qu'il soit réenregistré avec Analysis Services.